
Data Vault Pipeline Description (DVPD) is a concept and syntax to provide a universal data format, for storing all essential informations, that are needed to implement or generate a data loading process for a data vault model.
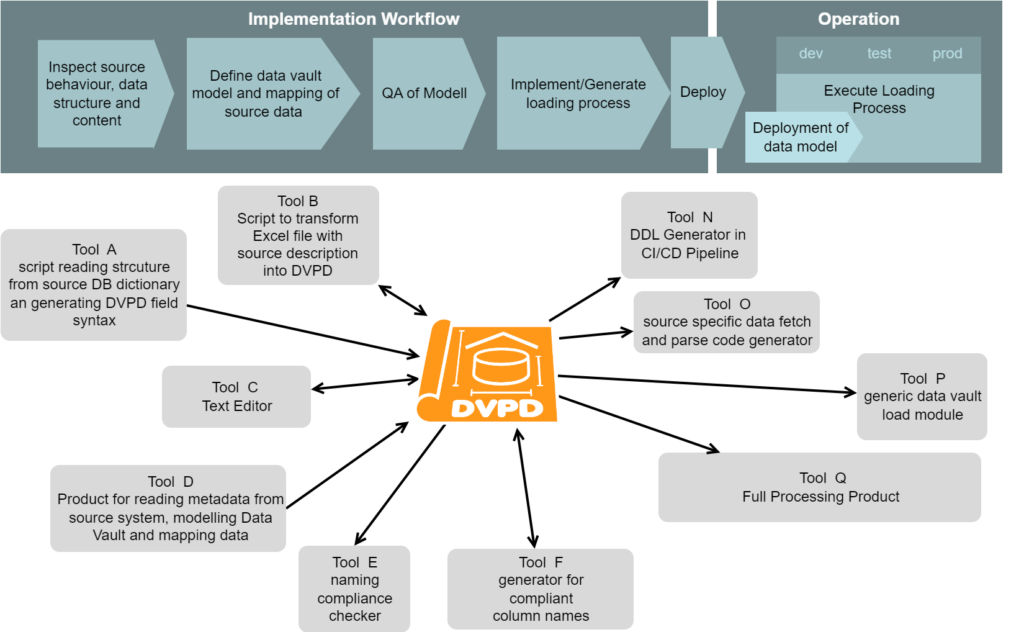
When established as standardized interface in the implementation workflow, DVPD decouples the implementation tools. Iterative extention and optimization of the toolset will have less impact on other steps. This will allow projects to select tools, that are taylored to the current needs of the project without blocking the option for later adjustments and enhancements.
Finally, as beeing a document, a DVPD can be treated as an encapsulated deployable artifact and therefore fits nicely into CI/CD workflows.
Motivation
Keeping the Data Vault implementation toolset agile
The implementation of loading processes for a data warehouse, is a complex task even when taking into account that Data Vault provides a lot of standardization and generalization. Many tools and frameworks try to support the Data Vault modelling and implementation process but in the end none can cover all steps.
That’s why data warehouse platforms often contain a bundle of tools with a mix of commercial or open source products and self written code. One major function needed in the implementation workflow, is the collection of the metadata, that is forged during the analysis and modelling steps and providing it to the implemtation steps. Unfortunatly, even after many projects an products have developed data structures to solve this problem in their own context, there is no solution, that can be used as a standardized and tool independent format.
This is where the DVPD concept steps in.
Goal and Scope
Full Data Vault support
DVDP will allow the declaration of all model structures and data mappings, that are possible in the Data Vault method. This also covers different approaches, how to implement row comparison, manage the enddating and detect actual data. The DVPD syntax might prevent declarations, that are not allowed/possible in the Data Vault method, but it is not the purpose of DVPD to fully enforce Data Vault compliance of models and mappings.
DVPD consuming tools (especially code generators and execution modules) might not support all Data Vault features and therefore all DVPD features. This is accepted, since projects might be competely satisfied with a reduced featureset. It is the responsibilty of these tools (or a checkscript the CI workflow) to warn about the usage of unsupported DVPD features.
All loading phases
DVPD contains information for all phases, that are necessary to load data from a data source. This includes declarations how to retrieve the data from the source, how to parse and transform the data into a tabularized representation and how to map it into a given data vault model. DVPD does not require an execution process, that solves all these steps in a single module. In contrary it enables the teams to combe different tools for different phases, all configured by a single arifact.
A Simple Example
To give you an impression about the syntax elements, lets take simpe example. It describes the loading of data from a simple database table named „Person“.
Lets first focus on the pure source structure declaration that is driven by the structure of the data source.

There is one declaration for every field of the source.
So lets continute with declaration of the target data vault model.

As you might notice, there are no column definitions in the target model. Only the tables, their data vault stereotype and their relations are declared.
Finally we need to map the fields to the target tables. This is also declared in the list of fields we have seen in the first step.
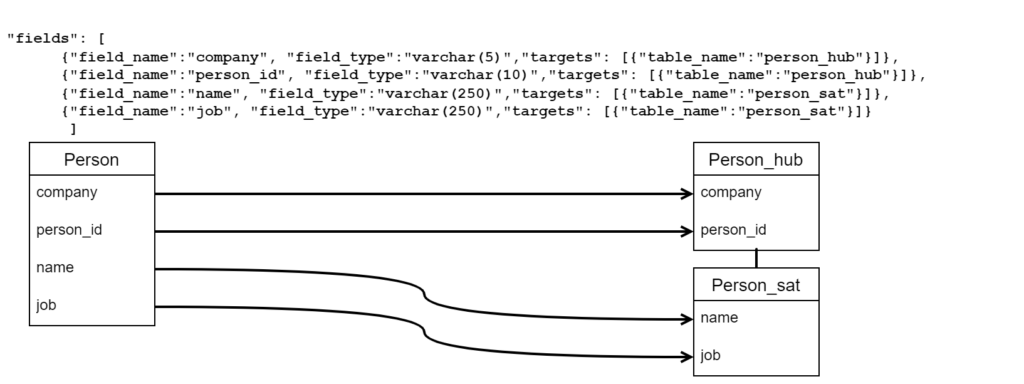
From the mapping of the source fields to the target tables, the columns of the target tables are induced. There are options to declare different names for the columns, but since it is best practice to name columns like their source fields, column names default to the field names.
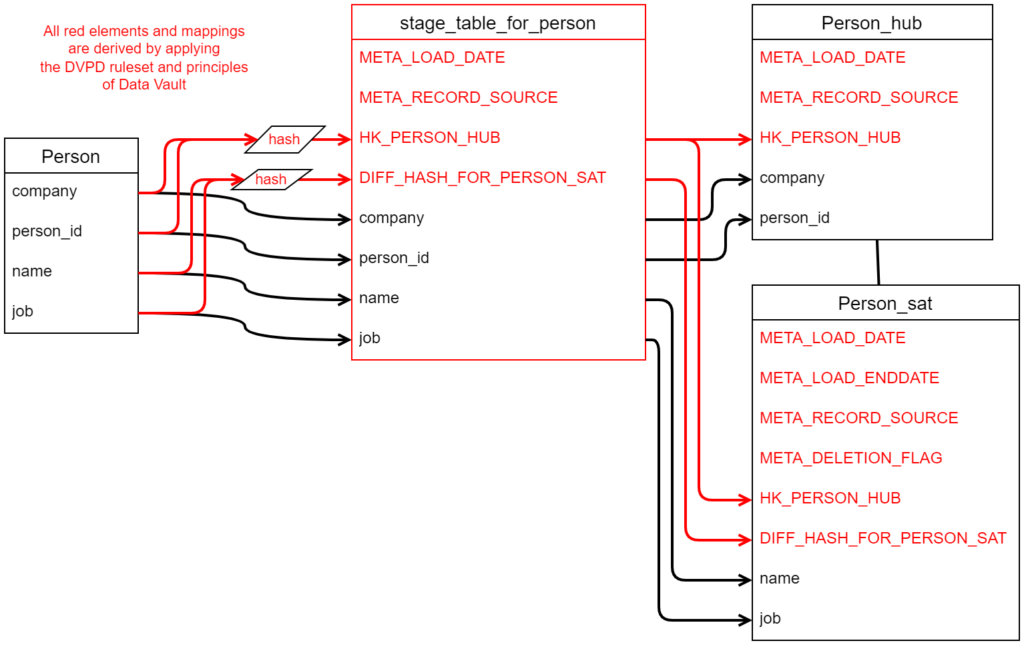
Applying DVPD interpretation rules
In many cases, the shown syntax of declaration is all, thats needed. All other informations for the loading process can be derived by following the interpretation rules:
- fields mapped to a hub are business keys in the hub
- fields mapped to a satellite are relevant for change detection
- the hub key column, needed for the hub will be named „HK_“ if not declared otherwise
- the key column name in the satellite will be the same as in the parent
Additionally there are general rule settings (called model profile), that are used by the whole project to keep consistency. In this example the following model profile settings are relevant:
- satellite comparison will use a diff hash
- satellites will be enddated
- satellites contain a deletion flag
- names for all the meta columns
This results in the following detailed data vault structure and mapping:
The complete DVPD of the example
Since there are some more declarations needed to describe the whole loading process, this is an example of a complete dvpd:

The main elements in a DVPD document
- Definition how to get data from the source (mostly defined by declaring an appropriate code generator or execution module, valid names depend on the toolset of the platform)
- Communication protocol
- Incremental retrieval method and behaviour
- method how to detect deleted data
- Definition how to parse the source data into rows and fields (highly depeding on the data format and capabilites of the parsing module)
- Target Datamodel
- Names and stereotypes of the data vault tables
- Relations between the tables
- Names of key and diff hash columns
- Declaration of the Model profile that has to be used (if not the default)
- Mapping of fields to the data model
- Name of target column (default = field name)
- Flags to exclude columns from hashes or comparison
- identification of the relevant relation (when there are multiple possibilities)
- Properties to the control order of columns in hash concatenation
For the full set of elements and their meaning, please look into the syntax reference.
Content of the Model Profile
The model profile, defines general properties, that should be the same for all loading processes
- Names and types of metadata columns
- Hashing method and value representation for hub keys and diff hashes
- Default settings for sattellite tables (e.g. if they have a diff hash)
- Values for ghost records
For the full set of elements and their meaing, please take a look into the syntax reference.
How to start ?
Read detailed documentation in the repository. Start here: DVPD_Introduction_and_orientation.md
Download the git repository from: https://github.com/cimt-ag/data_vault_pipelinedescription
It’s free
The DVPD concept is licensed under CC BY-ND 4.0, and the contained code under Apache-2.0
What’s in the repo ?
- Concept Documentation
- Description of the concept
- Reference of the core syntax of DVPD
- Installation and usersguide for the reference implementaition
- Analysis about the use case variations to cover by the syntax
- Data Mapping variation taxonomy
- Data Mapping dependend process generation
- Partitioned deletion scenarios
- Reference implementation of a DVPD compiler in python
- The compiler – Checking the DVPD syntax about its validity and compiling it into a full fledged instruction (DVPI)
- Testsets for the DVPD compiler
- Model crosscheck, to ensure model conistency over all dvpd/dvpi of a project
- Examples for generator scripts in python
- DDL script generator
- DBT model generator
- „Developer cheat sheet“ generator
- HTML Dokumentation generator
- Example for build scripts